Searching the Web--and being found
Search
sites are perhaps *the* most common starting point for Web
exploration. Search sites include "robot powered" search
engines and "human powered" subject guides to the 'net.
Readings
 Chapter 24 .
Chapter 24 .
Google bombing (wikipedia) -- George W. Bush's site was the top result in 2006 for Google searches for "miserable failure". Why/how?
Robot powered search engines
- Google,
Yahoo, Ask
- Amazon subsidiary A9 is notable for also showing "Search inside the book" results from amazon--requires amazon registration.
- Technorati indexes 'dynamic' content on the web--mostly blogs
Search engine's
approach the internet by indexing pages with a robot,
a piece of software that automatically reads pages, filing words that
it finds into a database, and then following links to more
pages. Robots or crawlers examine some portion of a web page, and note
every significant word on the page, and the address of the page.
Big
sites, like Google, must maintain a database of nearly the same size as all the pages it indexes--a large fraction of the web.
Search engine's find
out about new pages by three methods,
- People submit their site to be indexed,
- The search engine robot starts from a page (any page!) and follows all links to other pages, and so on. A paper by Barabassi and Jeong (1999) found an average of just 19 clicks between any two pages on the Internet.
- Google introduced the sitemap protocol in 2005, which provides a means for webmasters to upload lists of URLs to a search engine.
It typically takes several months for search engines to find a new page on the Web (without submission), let alone a new site. This can vary depending upon how high the profile of the site is (NY Times vs. your personal page).
Recent stats (see especially searchenginewatch.com's reports and Nielsen NetRatings results) find that Google is the most popular site (about 50% of all searches) followed by Yahoo, MSN and others.
In a 1999 research paper* Lawrence and Giles found:
- an estimated 800 million pages (1999),
- average text content of 19 Kb,
- no search engine site covered more than about 16% of the Web.
- together, the top 11 sites covered just 43% of the Web. (down from 60% two years earlier.
- Steve Lawrence and C. Lee Giles, Accessibility of information on the web, Nature, 8 July 1999, p. 107.
Search engines differ from each other in many respects, including:
- The depth of their coverage -- InfoSeek appears to cover fewer pages per site, but more sites compared to other search engines,
- The way they let you search their database,
- Whether they group all hits at the same site together, or not
- The order in which they present results (see below for more...)
- speed, how much of each page they index, coverage, whether or not they make available their own cache of the pages, etc.
Human powered subject guides
Subject guides are compiled by humans, much as a librarian would compile a subject index for a traditional card catalog.
Subject guides typically cover far fewer pages on the web, but far better. They often link only to the home page of a site.
Subject guides are often good starting points if you don't know exactly what kind of resources you're looking for.
Some highlights
- dir.Yahoo.com -- perhaps the most recognized subject guide to the web. Many businesses that depend on being found online view it as crucial to be listed here. Anyone can submit their site for free for Yahoo's editors to review for inclusion.
- Yahoo started with the subject guide, but yahoo.com is now more focused on search than subject guide. To make matters slightly confusing, Yahoo's search box returns results not only from its hierarchical subject guide compiled by humans, but also from the internet at large, and it's powered by Google.
- Open directory project -- Similar metaphor for subject guides to the web, but they hope to do a better job by harvesting the volunteer efforts of many more people worldwide than Yahoo can pay as editors.
Searching tips
The main tip (Thanks to Sally Jo Milne) is to choose one or two search engines, and then get familiar with them, and read the help files.
- Insert your search in quotations: "George Washington" instead of George+Washington.
- Add * or ? to the root word of your search. E.g: "Fish*" or "Fish?" could lead you to pages with the words. Fishing, Fisher, Fishermen, Fished, etc.
Boolean searching
You should know the difference between pages which contain mention of:
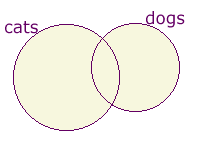 cats or dogs. (Hotbot lingo "any words")
cats or dogs. (Hotbot lingo "any words")
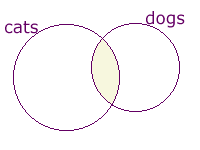 cats and dogs (Hotbot lingo "all words")
cats and dogs (Hotbot lingo "all words")
 cats and not dogs (on Google, you'd search for +dogs -cats)
cats and not dogs (on Google, you'd search for +dogs -cats)
Other search refinements:
Solve crimes with Google!
- You can often search for phrases by enclosing within quotes, e.g "George Washington".
- Use Google to search a particular site, e.g. fetal pig +site:goshen.edu
- Choosing low-frequency words/names or place names.
- See the GC library's page of Search engine tips for more.
SEO - Search Engine Optimization: Writing for top billing
If someone types "grackles" into a search engine site, how can you insure that your page will come up on the first page of search results? Here are some of the things that search engines consider in deciding on their page rankings:
- Does the word occur in the URL? E.g. www.grackles.com, www.goshen.edu/gracklepoems.html.
- Does the word occur in the title of the page? E.g. <title>Grackles poetry</title>
- Does the word occur in a headline rather than in body text? E.g. <h1>Poems about grackles</h1>
- Does the word occur in (many of) the link labels for links to your site from others?
- Google also includes in its calculations a measure of how many other web pages are linking to yours. One consequence of this is that if at all possible, you should not change the URL of a web page that you're modifying because you're likely to lose the benefit of any sites that have linked to your previous content.
- Most search engines (but *not* Google) have some variation on the theme of paying to be featured prominently. Google has a (very effective) "ad words" program, but ad words sites are kept visually separate from the search results.
Google also includes in its index words in the alt attribute of images. See this chart comparing what tags search engines pay attention to.
<meta> tags
<HTML>
<HEAD>
<TITLE>Poems about rackles</TITLE>
<META NAME="Author" CONTENT="Paul Meyer Reimer">
<META NAME="Description" CONTENT="This page is an homage to grackles">
<META NAME="Keywords" CONTENT="grackle, birds, poetry, writing">
</HEAD>
Meta tags contain information about the page, but are not displayed on the page. Search engines now mostly ignore the meta keywords tag, because they were too heavily spammed. So currently meta tags are mainly useful for your own site's crawlers, except for...
Controlling the (nice) robots
Some useful, and fairly self-explanatory tags. No guarantee that spam-bots pay any attention, of course.
<META NAME="ROBOTS" CONTENT="NOINDEX">
<META NAME="ROBOTS" CONTENT="NOARCHIVE">
For more related information, search the web for robots.txt.